

Research Scientist at Alibaba DAMO Academy, Beijing
Ph.D from Tsinghua University, advised by Prof. Gao Huang and Prof. Shiji Song
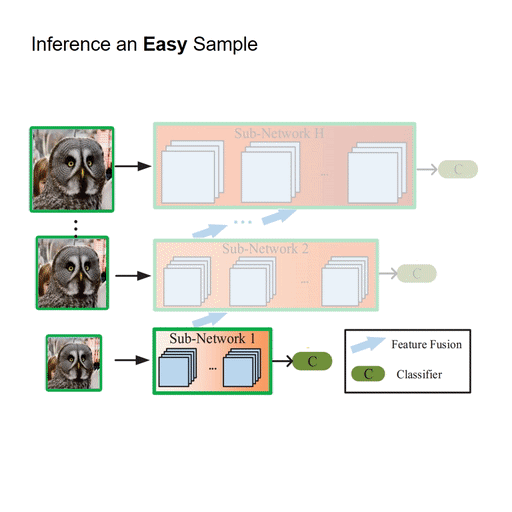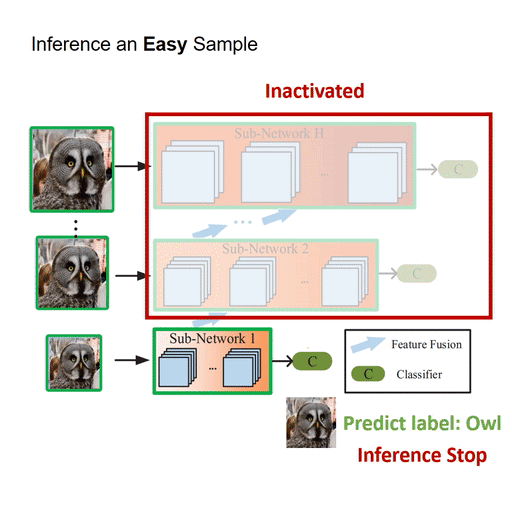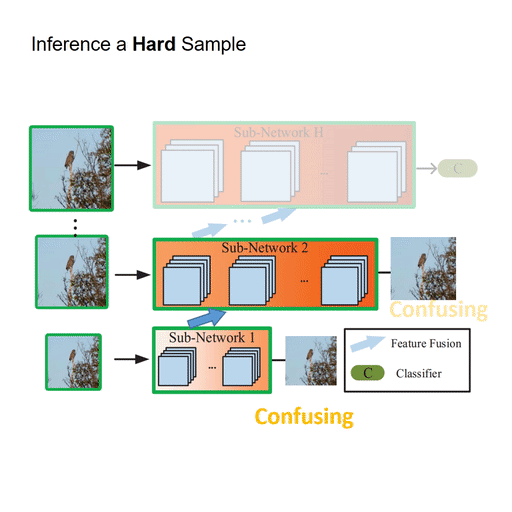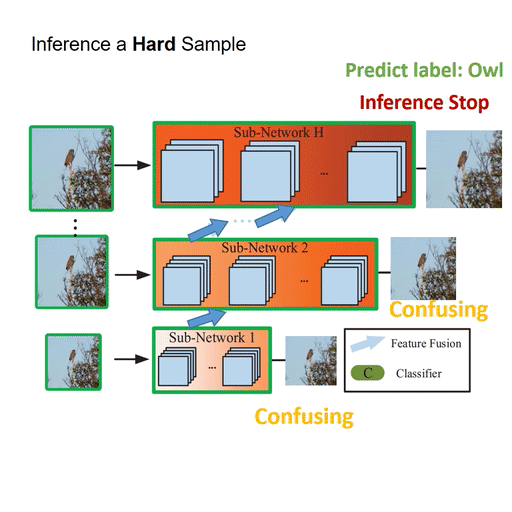
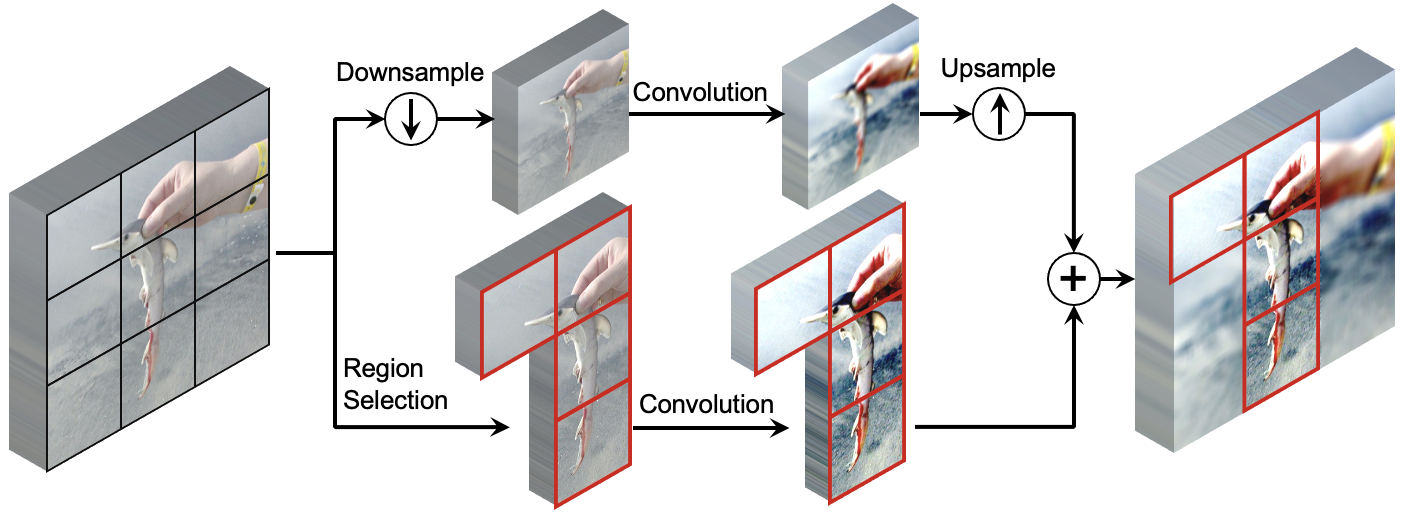
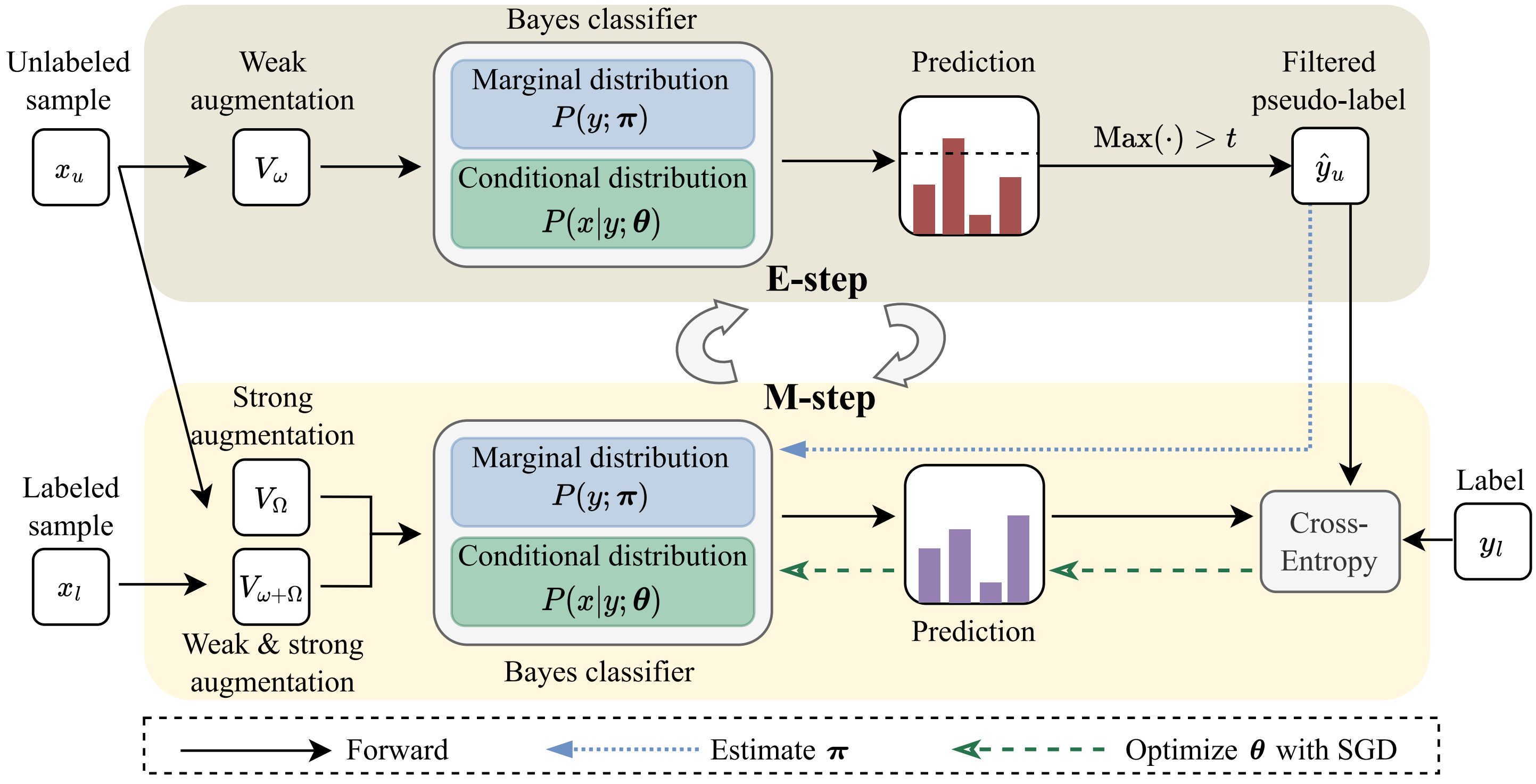
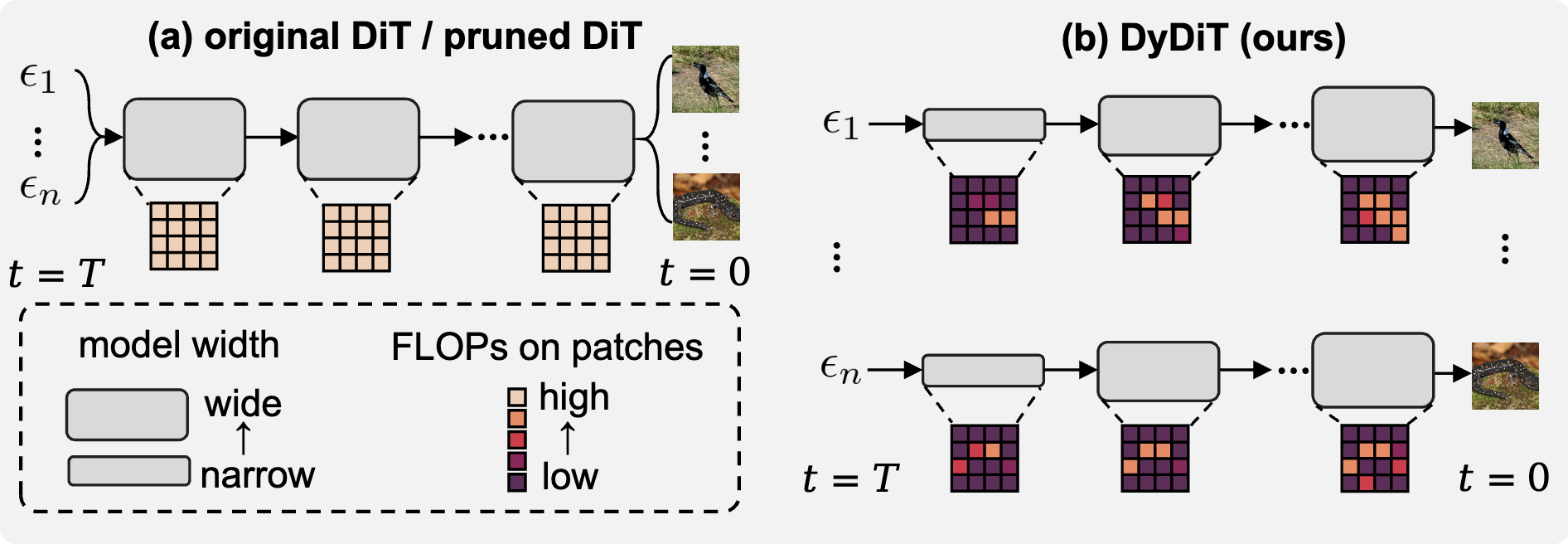
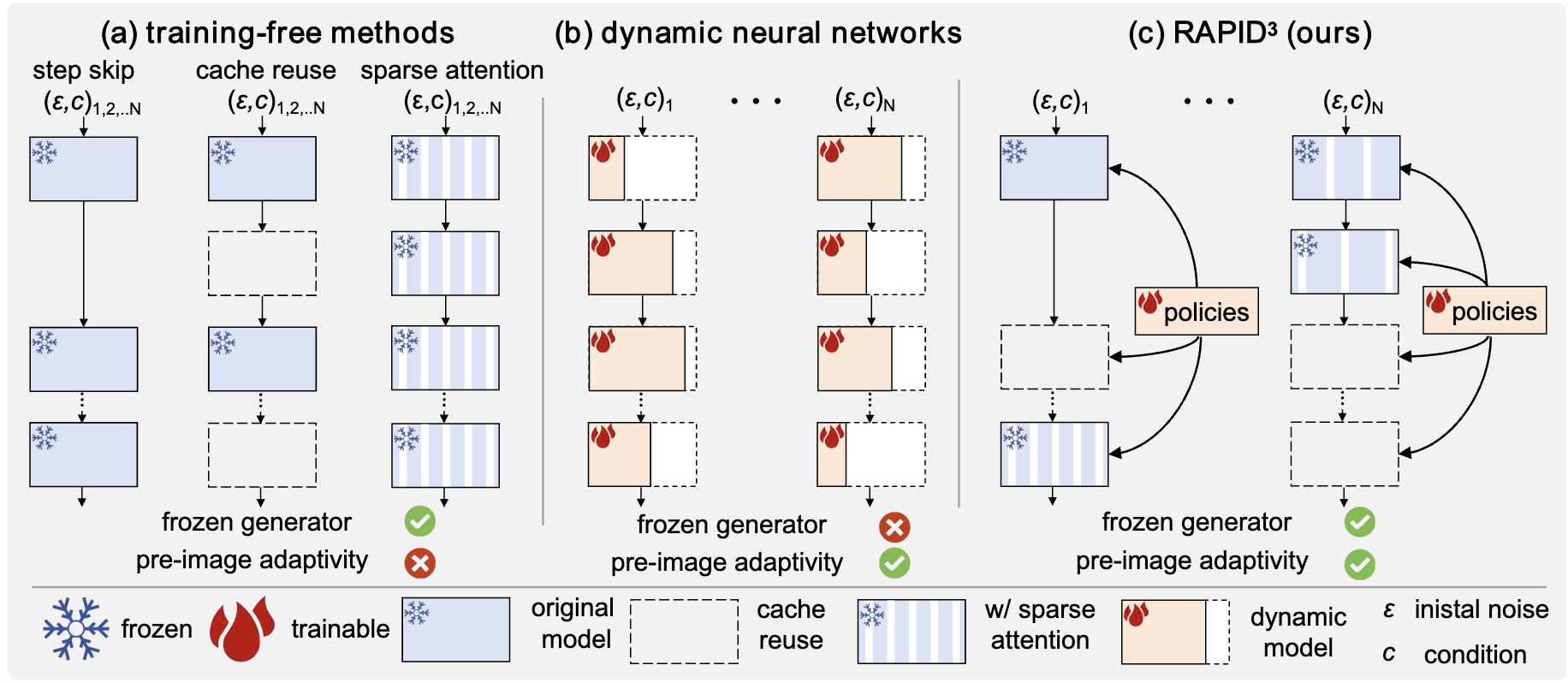
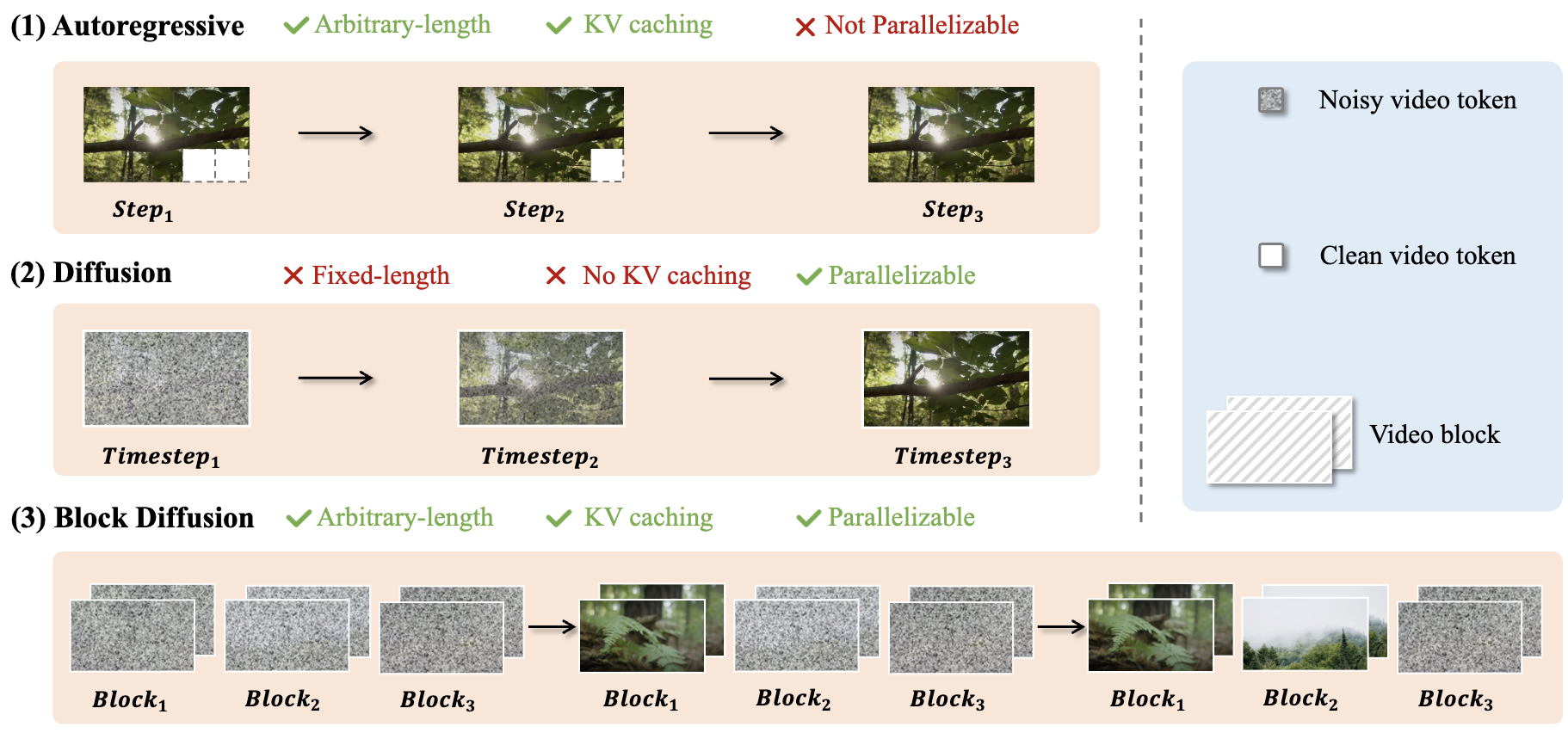
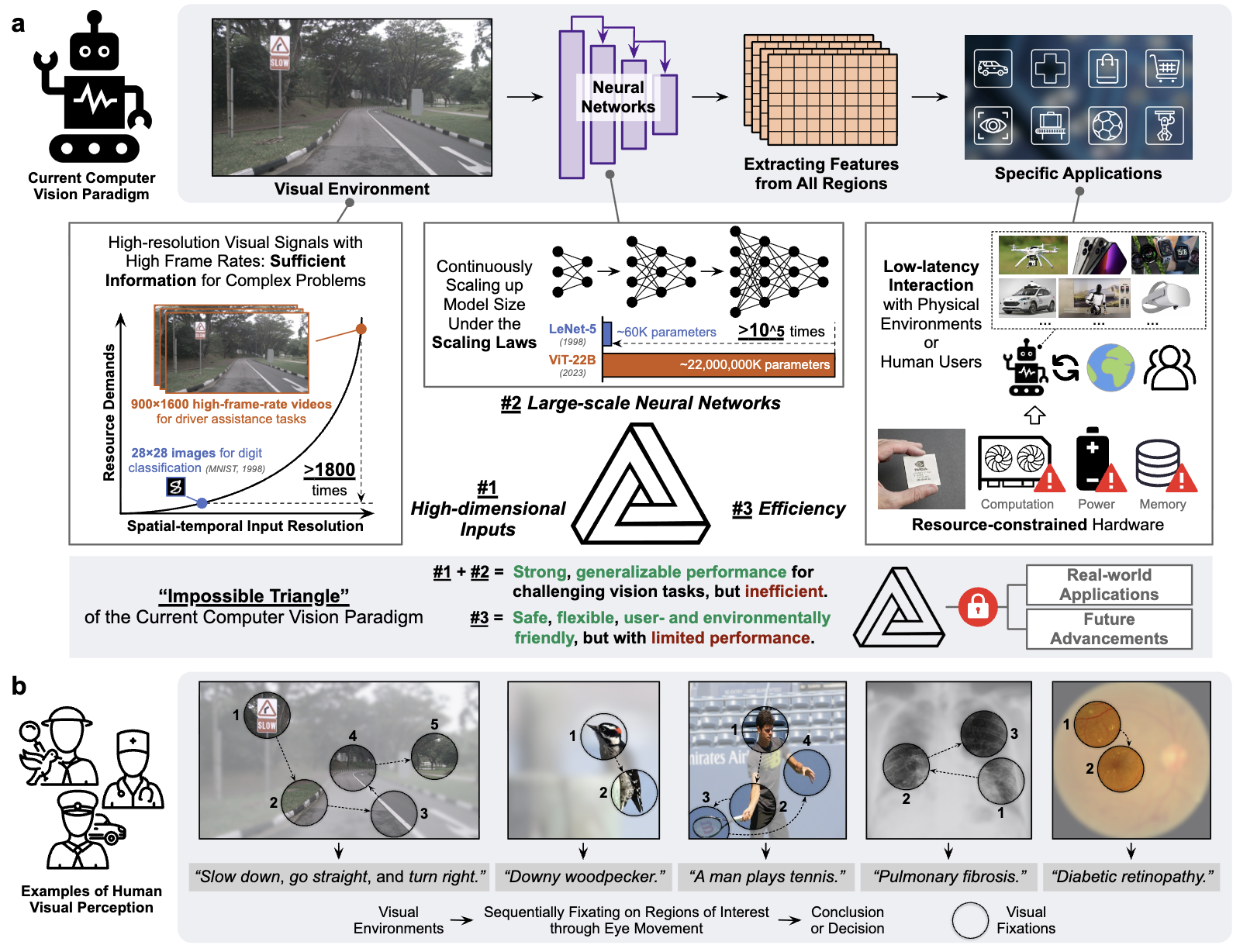
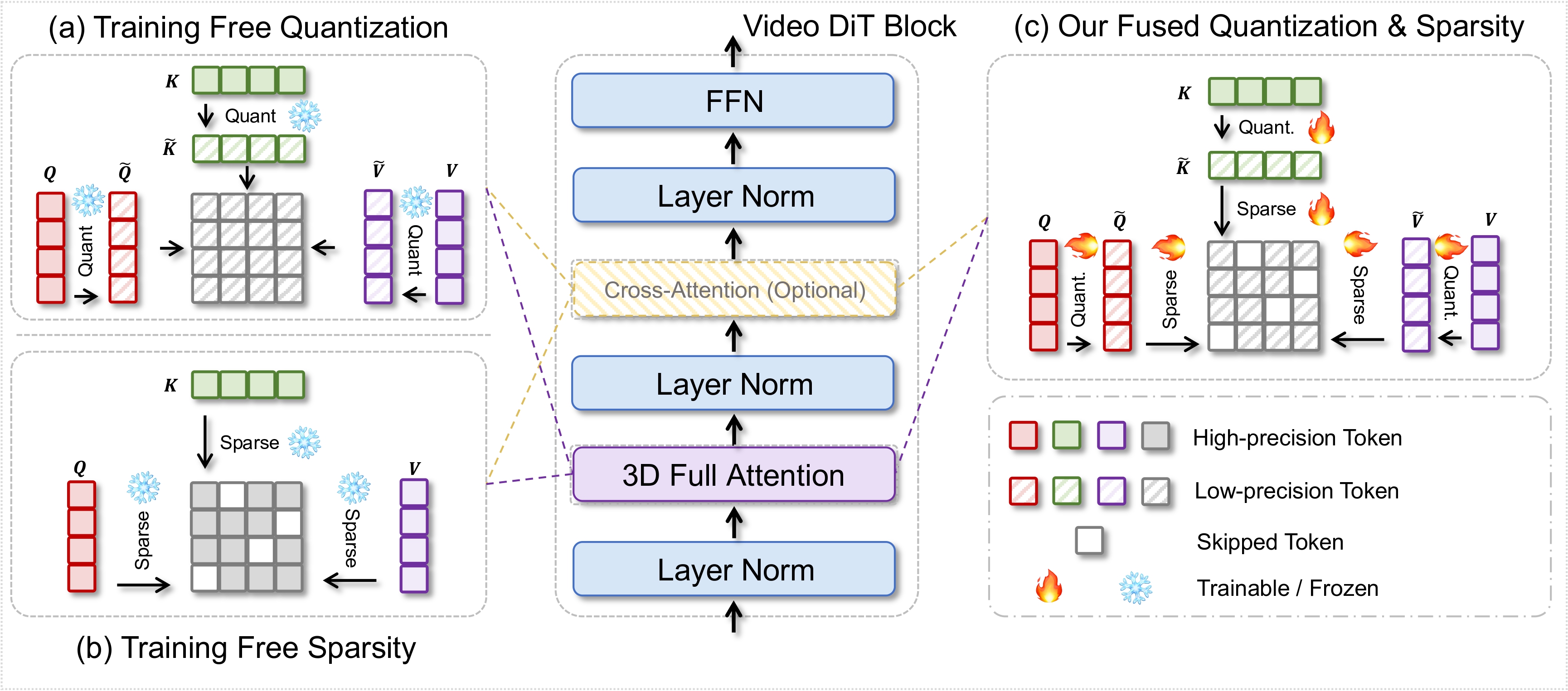
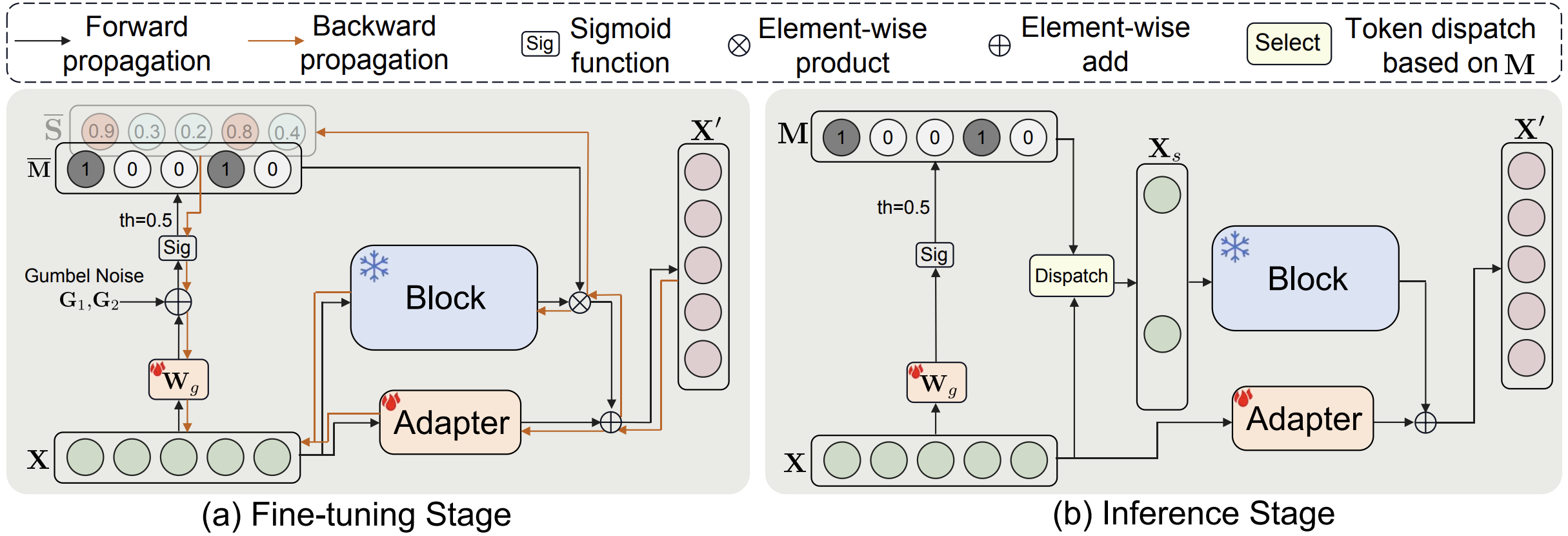
My research focuses on deep learning, computer vision and medical AI, in particular dynamic neural networks and efficient learning/inference of deep models in resource-constrained scenarios.
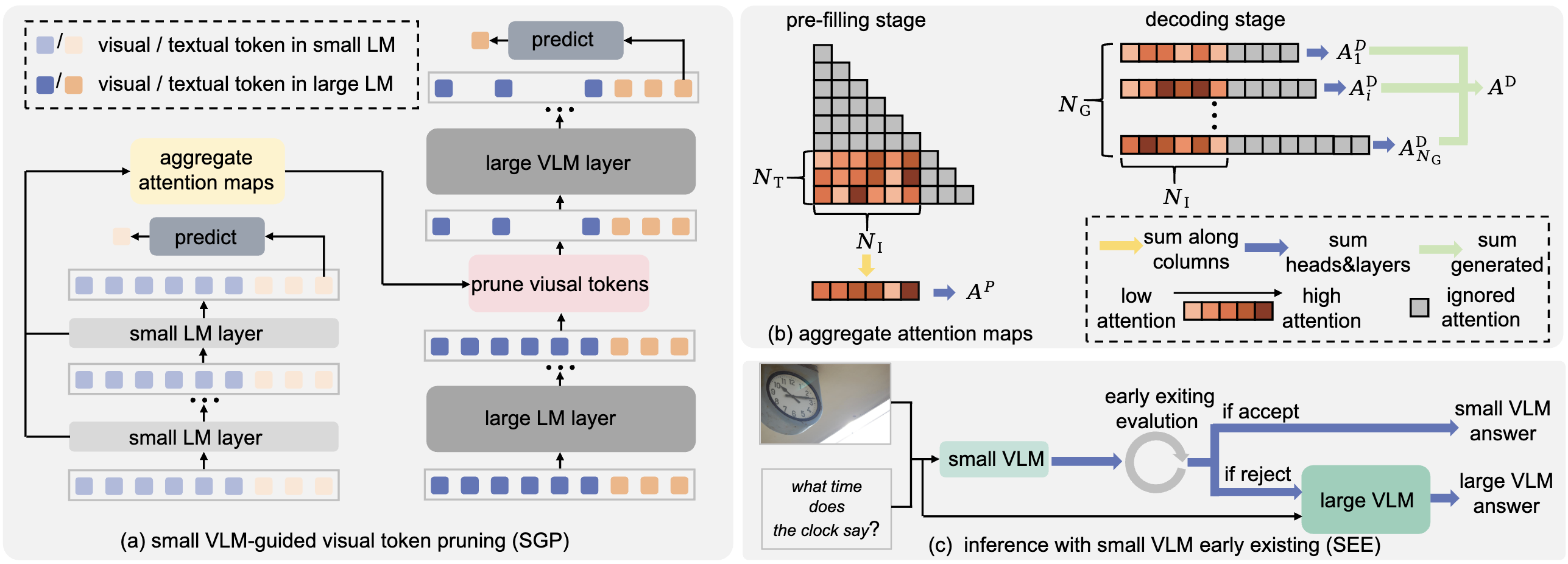
Recently, I am interested in directions related to Efficient/Dynamic Vision Language Model (VLM), Visual Generation, and scalable medical AI systems.
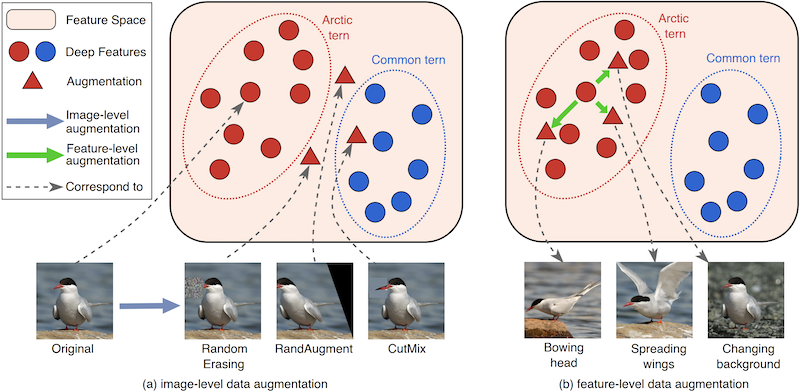
I'm also interested in fundamental machine learning problems, such as semi-supervised long-tailed learning and fine-grained learning.